Just enough to make some sense
I've realized that my previous post on language and semantics could possibly be a bit hard to understand without having the proper context wrapped around it, so today I'll continue my journey of explaining life, universe and everything. Today I want to talk about "just enough complexity for understanding, but not more."
Mouses
Let's talk about mouse. Or a mouse. Mice. Let's talk about this ;

One can argue whether this is really enough context for us to talk about this thing. What does "mouse" mean here? The Disney mouse? A computer mouse? The mouse shadow in the second moon? In order for me to communicate clearly with my fellow human beings I need to provide just enough information so that we can figure this out, so I say "mouse, you know the furry, multivorus, small critter that ..." ;

This is too much information, at least for most cases. I'm not trying to give you all the information I know about mice, but just enough for me to say "I saw a mouse yesterday in the pantry." Talking about context is incredibly hard, because, frankly, what does context mean? And how much background information do I need to provide to you in order for you to understand what I'm talking about?
In terms of language "context" means verbal context as words and expressions that surrounds a word, and social context as the connection between the words and those who hear or read them based on the human constraints (age, gender, knowledge, etc.) There's also some controversy about this, and we often also imply certain mental models (social context of understanding).
In general, though, we talk about context as "that stuff that surrounds the issue", from solid objects, ideas, my mental state, what I see, what I know, what my audience see and knows, hears, smells, cultural and political history, musical tastes, and on and on and on. Everything in the moment and everything in the past in order to understand the current communication that takes us to the future.
Yup, it's pretty big and heady stuff, and it's a darn interesting question; how much context do you need in order to communicate well? My previous post was indeed about how much context we need to put into our language and definition in order to communicate well.
A bit of background
Back in 1956 a paper by the cognitive psychologist George A. Miller changed a lot of how we think about our own capacity for juggling stuff in our heads. It's a most famous paper, where further research since has added to and confirmed the basic premise that there's only so much we're able to remember at the same time. And the figure that came up was 7, plus / minus 2.
Of course that number is specific to that research, and may mean very little in the scheme of more specific settings. It's a general rule, though, that hints to the limits we have in cognition, in the way we observe and respond to communication. And it certainly helps us understand the way we deal with context. Context can be overly complex, or overly simple. Maybe the right amount of context is 7, plus / minus 2?
Just right

I'm not going to speculate much in what it means that "between 5 and 9 equally-weighted error-less choices" defines arbitrary constraints on our mental storage capacity (short-term especially), but I'll for sure speculate that it guides the way we can understand context, and perhaps especially where it's loosely defined.
We humans have a tendency to think that those things that looks like the truth must be the truth. We do this perhaps especially in the way we deal with computer systems, because, frankly, it's easy to define structures and limitations there. It's what we do.
An example of this is how we observe anything as containers that may contain things, that in themselves might be containers which might be things or more containers, and so on. Our world is filld with this notion, from taxonomies, to object-oriented programming, to XML, to how we talk bout structures and things, to how science was defined, and on and on and on. Tree-structures, basically.
But as anyone with a decent taxonomic background knows, taxonomies don't always work as a strict tree-structure. Neither does anyone who's meddled in OO for too long. Or fiddled with XML until the angle-brackets break. These things looks so much like the truth that we pursue them as truth.
things are more chaotic than we like. They're more, in fact, like graph structures, where relationships between things go back and forth, up and down, over and under already established relationships. It can be quite tricky, because the simple "this container contains these containers" mentality is gone, and a more complex model appears;
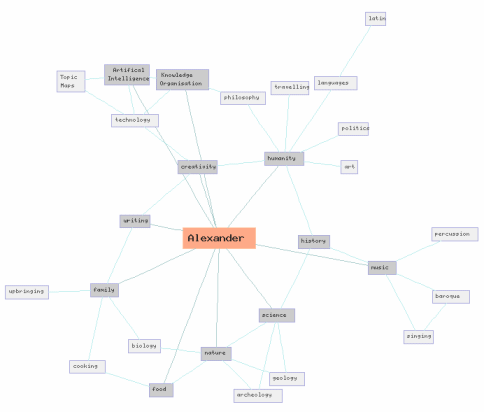
This is the world of the Semantic Web and Topic Maps, of course, and many of the reasons why these emerging technologies are, er, emerging is of course because all containers aren't containers at all, and that the semantics of "this things belongs to that thing" isn't precise enough when we want to communicate well. Explaining the world in terms of tree-structures puts too many constraints on us, so many that we spend most our time trying to fit our communication into it rather than simply defining them.
We could go back to frames theory as well, with recursive key/value properties that you find naturally in b-trees, where values are either a literal, or another property. RDF is based on this model, for example, where the recursiveness is used for creating graph structures. (Which is one reason I hate RDF, using anonymous nodes for literals)
Programming languages and meta models
Programming languages don't extend the basic pre-defined model of the language much. Some languages allow some degree of flexibility (such as Ruby, Lisp and Python), some offer tweaking (such as PHP. Lua and Perl), while others offer macroing and overloading of syntax (mostly C family), and yet more are just stuck in their modeling ways (Java). [note: don't take these notions too strictly; there's a host of features to these languages that mix and match various terms, both within and outside of the OO paradigm]
What they all have in common is that the defined meta model is linked to shifting bits and bytes around a computer program, and that all human communication and / or understanding is left in the hands of programmers. Let's talk about meta models.
Most programming languages have a set of keywords and syntax that make up a model of programming. this is the meta model; it's a foundation of a language, a set of things in which you build your programs on. All programming languages have more or less of them, and the more they have, the stricter they usually are as well. Some are object oriented languages, other functional, some imperative, and yet other mixes things up. If I write ;
Int i = new Int ( 34) ;
in Java, there's only so many ways to interpret that. It's basically an instance of the Integer class, that holds the integer number of 34. But what about
$i = new Int ( 34 ) ;
in PHP? There is no built-in class called Int in PHP, so this code either fails or produce an instance of some class called Int, but we do not know what that means, at least not at this point. And this is what the meta model defines; built-in types, classes, APIs and the overall framework, how things are glued together.
As such, Java and .Net has huge meta models defined, so huge that you can spend your whole career in just one part of it. PHP has a medium meta model, Perl even smaller, all the way down to assembler with a rather puny meta model. Syntax and keywords is not just how we program, but they define the constraints of our language. There's things that's easy and hard in every language, and there is no one answer to what the best programming language is. They all do things differently.
The object-oriented ways of Java differ to the ones of Ruby which differs to the ways of C++ which differs to the ways of PHP. The functional ways of Erlang differs to XSLT which differs to Lisp.
The right answer?
There is no right answer. One can always argue about the little differences between all thse meta models, and we do, all the time. We bicker about operator overloading, about whether mutliple inheritance is better than single inheritance, one the real difference between interfaces and abstract classes, about getter and setter methods (or lack thereof), about types should be first class objects or not, about what closures are, wheter to use curly-brackets or define programming structure through whitespace, and .
My previous post was another way of saying that we perhaps should argue less about the meta model of our language, and worry more about the reason the computer was created more than how a certain problem was solved? We don't have the mental capacity to juggle too much stuff around in our brains, and if the meta model is huge, our ability to focus on perhaps the important bits become less.
There are so many levels of communication in our development stack. Maybe we should introduce a more semantically sane model into it to move a few steps closer to the real problem, the communication between man and machine? I'm not convinced that OO nor functional programming solves the human communication problem. let's speculate and draw sketches on napkins.
Mouses
Let's talk about mouse. Or a mouse. Mice. Let's talk about this ;
One can argue whether this is really enough context for us to talk about this thing. What does "mouse" mean here? The Disney mouse? A computer mouse? The mouse shadow in the second moon? In order for me to communicate clearly with my fellow human beings I need to provide just enough information so that we can figure this out, so I say "mouse, you know the furry, multivorus, small critter that ..." ;
This is too much information, at least for most cases. I'm not trying to give you all the information I know about mice, but just enough for me to say "I saw a mouse yesterday in the pantry." Talking about context is incredibly hard, because, frankly, what does context mean? And how much background information do I need to provide to you in order for you to understand what I'm talking about?
In terms of language "context" means verbal context as words and expressions that surrounds a word, and social context as the connection between the words and those who hear or read them based on the human constraints (age, gender, knowledge, etc.) There's also some controversy about this, and we often also imply certain mental models (social context of understanding).
In general, though, we talk about context as "that stuff that surrounds the issue", from solid objects, ideas, my mental state, what I see, what I know, what my audience see and knows, hears, smells, cultural and political history, musical tastes, and on and on and on. Everything in the moment and everything in the past in order to understand the current communication that takes us to the future.
Yup, it's pretty big and heady stuff, and it's a darn interesting question; how much context do you need in order to communicate well? My previous post was indeed about how much context we need to put into our language and definition in order to communicate well.
A bit of background
Back in 1956 a paper by the cognitive psychologist George A. Miller changed a lot of how we think about our own capacity for juggling stuff in our heads. It's a most famous paper, where further research since has added to and confirmed the basic premise that there's only so much we're able to remember at the same time. And the figure that came up was 7, plus / minus 2.
Of course that number is specific to that research, and may mean very little in the scheme of more specific settings. It's a general rule, though, that hints to the limits we have in cognition, in the way we observe and respond to communication. And it certainly helps us understand the way we deal with context. Context can be overly complex, or overly simple. Maybe the right amount of context is 7, plus / minus 2?
Just right
I'm not going to speculate much in what it means that "between 5 and 9 equally-weighted error-less choices" defines arbitrary constraints on our mental storage capacity (short-term especially), but I'll for sure speculate that it guides the way we can understand context, and perhaps especially where it's loosely defined.
We humans have a tendency to think that those things that looks like the truth must be the truth. We do this perhaps especially in the way we deal with computer systems, because, frankly, it's easy to define structures and limitations there. It's what we do.
An example of this is how we observe anything as containers that may contain things, that in themselves might be containers which might be things or more containers, and so on. Our world is filld with this notion, from taxonomies, to object-oriented programming, to XML, to how we talk bout structures and things, to how science was defined, and on and on and on. Tree-structures, basically.
But as anyone with a decent taxonomic background knows, taxonomies don't always work as a strict tree-structure. Neither does anyone who's meddled in OO for too long. Or fiddled with XML until the angle-brackets break. These things looks so much like the truth that we pursue them as truth.
things are more chaotic than we like. They're more, in fact, like graph structures, where relationships between things go back and forth, up and down, over and under already established relationships. It can be quite tricky, because the simple "this container contains these containers" mentality is gone, and a more complex model appears;
This is the world of the Semantic Web and Topic Maps, of course, and many of the reasons why these emerging technologies are, er, emerging is of course because all containers aren't containers at all, and that the semantics of "this things belongs to that thing" isn't precise enough when we want to communicate well. Explaining the world in terms of tree-structures puts too many constraints on us, so many that we spend most our time trying to fit our communication into it rather than simply defining them.
We could go back to frames theory as well, with recursive key/value properties that you find naturally in b-trees, where values are either a literal, or another property. RDF is based on this model, for example, where the recursiveness is used for creating graph structures. (Which is one reason I hate RDF, using anonymous nodes for literals)
Programming languages and meta models
Programming languages don't extend the basic pre-defined model of the language much. Some languages allow some degree of flexibility (such as Ruby, Lisp and Python), some offer tweaking (such as PHP. Lua and Perl), while others offer macroing and overloading of syntax (mostly C family), and yet more are just stuck in their modeling ways (Java). [note: don't take these notions too strictly; there's a host of features to these languages that mix and match various terms, both within and outside of the OO paradigm]
What they all have in common is that the defined meta model is linked to shifting bits and bytes around a computer program, and that all human communication and / or understanding is left in the hands of programmers. Let's talk about meta models.
Most programming languages have a set of keywords and syntax that make up a model of programming. this is the meta model; it's a foundation of a language, a set of things in which you build your programs on. All programming languages have more or less of them, and the more they have, the stricter they usually are as well. Some are object oriented languages, other functional, some imperative, and yet other mixes things up. If I write ;
Int i = new Int ( 34) ;
in Java, there's only so many ways to interpret that. It's basically an instance of the Integer class, that holds the integer number of 34. But what about
$i = new Int ( 34 ) ;
in PHP? There is no built-in class called Int in PHP, so this code either fails or produce an instance of some class called Int, but we do not know what that means, at least not at this point. And this is what the meta model defines; built-in types, classes, APIs and the overall framework, how things are glued together.
As such, Java and .Net has huge meta models defined, so huge that you can spend your whole career in just one part of it. PHP has a medium meta model, Perl even smaller, all the way down to assembler with a rather puny meta model. Syntax and keywords is not just how we program, but they define the constraints of our language. There's things that's easy and hard in every language, and there is no one answer to what the best programming language is. They all do things differently.
The object-oriented ways of Java differ to the ones of Ruby which differs to the ways of C++ which differs to the ways of PHP. The functional ways of Erlang differs to XSLT which differs to Lisp.
The right answer?
There is no right answer. One can always argue about the little differences between all thse meta models, and we do, all the time. We bicker about operator overloading, about whether mutliple inheritance is better than single inheritance, one the real difference between interfaces and abstract classes, about getter and setter methods (or lack thereof), about types should be first class objects or not, about what closures are, wheter to use curly-brackets or define programming structure through whitespace, and .
My previous post was another way of saying that we perhaps should argue less about the meta model of our language, and worry more about the reason the computer was created more than how a certain problem was solved? We don't have the mental capacity to juggle too much stuff around in our brains, and if the meta model is huge, our ability to focus on perhaps the important bits become less.
There are so many levels of communication in our development stack. Maybe we should introduce a more semantically sane model into it to move a few steps closer to the real problem, the communication between man and machine? I'm not convinced that OO nor functional programming solves the human communication problem. let's speculate and draw sketches on napkins.
Labels: java, language, php, programming, programming languages, semantic web, semantics, topic maps